

Container Security for AI Agent and LLM Workloads
Your GPU base image ships with thousands of CVEs before a single model weight loads. Your scanner flags hundreds of findings, your team triages for days, and nothing actually gets fixed. This post covers the specific failure modes that hit ML platform teams hardest and the practical steps that cut real risk.
What ML Teams Get Wrong with Container Image Security
Most teams treat AI workloads like ordinary web services. They pull a CUDA or PyTorch base image, layer on their dependencies, and run a scan. The results are brutal: hundreds or thousands of findings, most tied to packages the runtime never touches.
The real problem is that GPU base images and AI frameworks carry enormous dependency trees by design. Framework authors optimize for compatibility, not minimal footprint. That means your inference server image inherits libraries for database drivers, image codecs, and system utilities your model never calls.
Scanner noise makes this worse. When every image has 400 findings, engineers stop treating alerts as signals. Teams normalize high CVE counts and ship anyway, because the alternative is manual triage that never ends.
“We fixed nothing for three sprints because every fix opened five new scanner tickets. At some point, you ship the vulnerability and hope for the best.”
The smarter question is not “how many CVEs exist?” but “which ones can actually execute at runtime?”
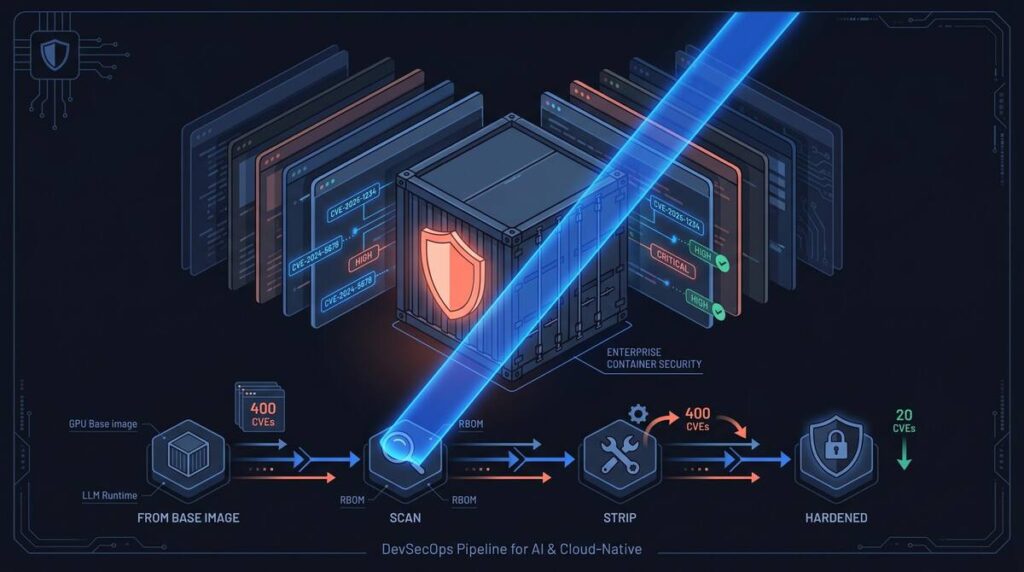
Container security pipeline for AI workloads: from bloated GPU base image through runtime profiling to hardened container with 95% CVE reduction
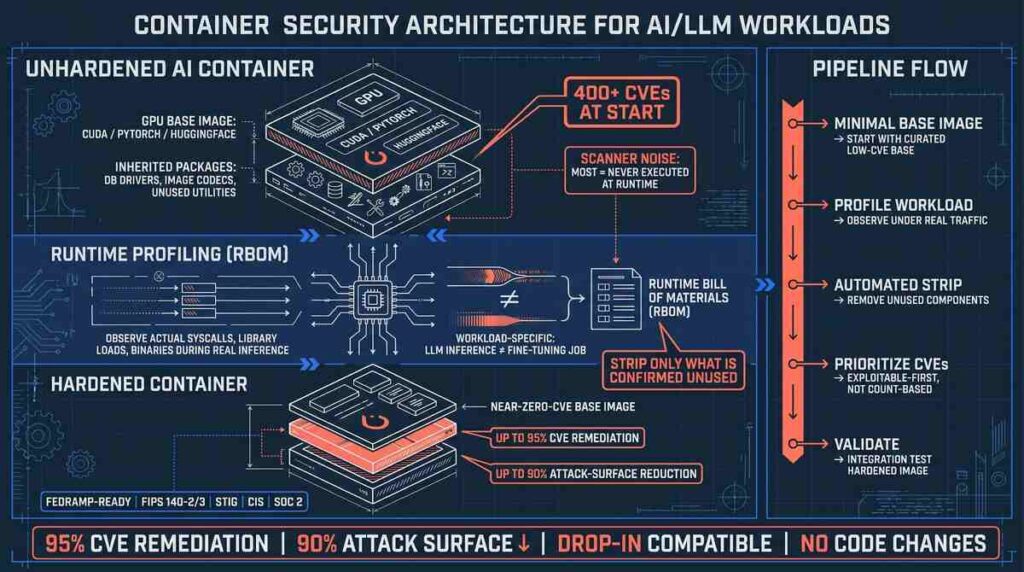
Structural breakdown of container security architecture for AI/LLM workloads: unhardened image, runtime profiling layer, and hardened output with compliance posture
Criteria Checklist for Evaluating Container Security for AI Workloads
Not every hardening approach fits ML infrastructure. Use these criteria to evaluate what will actually work.
Near-Zero-CVE Base Images
You need a catalog of curated base images built for minimal attack surface – not just patched versions of bloated defaults. What it means in practice: drop-in replacements for Alpine, Debian, UBI, and Ubuntu LTS that carry dramatically fewer inherited vulnerabilities from day one. Without this, you start every build already in debt.
Per-Workload Runtime Profiling
A static scan cannot tell you which packages your LLM inference server actually executes. Runtime profiling observes what the container calls during real workloads and produces a runtime bill of materials. What it means in practice: you strip only components confirmed unused, not guesses. Without this, you either over-strip and break the model or under-strip and leave exposure in place.
Automated CVE Remediation
Manual hardening of ML images does not scale. A good solution automates the removal of unused components and applies patches without requiring you to rebuild from source or rewrite Dockerfiles. What it means in practice: your hardening keeps pace with upstream changes. Without automation, the gap between scan and fix grows every release cycle.
Drop-In Compatibility
Any hardening approach that forces a build-system migration or OS-level rewrite will stall. The criteria here is simple: swap the base image, run the workload, ship. What it means in practice: your existing pipelines, model serving frameworks, and GPU drivers continue to work. Without drop-in compatibility, hardening becomes a multi-sprint project, not a one-day task.
Focus on Exploitable Risk, Not Scan Noise
A tool that floods you with static findings is not a security tool – it is an anxiety generator. You need prioritization that separates vulnerabilities present in executing code from those in packages that never run. What it means in practice: your team works a short, validated list. Without this filter, alert fatigue kills the program.
Compliance Posture
AI workloads increasingly run in regulated environments. Look for coverage of FedRAMP-Ready, FIPS 140-2/140-3, STIG, CIS, and SOC 2 controls. What it means in practice: your hardened images satisfy audit requirements without separate compliance tooling. Without this, you carry two parallel tracks: security and compliance.
How to Harden Container Images for AI Agent Runtimes
These five steps apply whether you are running a single LLM inference endpoint or a multi-agent pipeline with dozens of containers.
Start with a minimal, curated base image. Do not pull the official CUDA or framework image and hope for the best. Choose a base image built specifically for low CVE count and small attack surface. Tools that offer hardened container images as catalog items let you swap without touching your build logic.
Profile each container under realistic workload conditions. Run your inference server, your agent orchestration layer, and your embedding service under actual traffic patterns before you strip anything. A runtime profiler observes which libraries, binaries, and syscalls the process actually invokes. Strip decisions made from static analysis alone will break model-serving code in unpredictable ways.
Automate remediation in your CI pipeline. Hardening should not be a one-time event. Wire your profiling and stripping step into the build pipeline so every new image version gets the same treatment. The cost of that step is low; the cost of skipping it on a patched upstream image is not.
Prioritize CVEs by executability, not count. When your tool surfaces findings, filter first for vulnerabilities in packages confirmed to execute at runtime. A CVE in a library your container loads and calls is categorically different from one in a package that ships in the image but never runs. Treating them equally wastes remediation budget.
Validate the hardened image against your integration test suite. After stripping, run your full test suite against the hardened image before promotion. This step catches the rare case where profiling missed a cold-path dependency. It adds minutes to your pipeline; catching a broken model in production costs days.
Consistent application of these steps can produce up to 95% CVE remediation and up to 90% attack-surface reduction without touching model code or pipeline architecture.
Frequently Asked Questions
Does container hardening break GPU drivers or CUDA compatibility?
It can, if the hardening tool strips without runtime evidence. Tools that rely purely on static analysis will sometimes remove libraries that CUDA loads dynamically. Profiling-based hardening observes actual GPU initialization paths and preserves what the driver stack needs.
How do I handle the huge dependency trees that frameworks like PyTorch or Hugging Face pull in?
The key is workload-specific profiling, not a generic trim. An LLM inference workload uses a different subset of the PyTorch dependency tree than a fine-tuning job. Profile each container type separately and strip independently. Generic “AI framework” hardening profiles miss this distinction.
What tool actually combines curated base images, runtime profiling, and automated remediation in one workflow?
RapidFort offers end-to-end container vulnerability management that ties together a catalog of near-zero-CVE drop-in base images, per-workload runtime profiling (RBOM), and automated hardening with no code or pipeline changes required. It is one of the few platforms that connects the profiling step directly to remediation rather than leaving that gap to manual work.
Does this approach satisfy compliance requirements for regulated AI deployments?
Yes, if the hardening platform supports the relevant control frameworks. Look for coverage of FedRAMP-Ready, FIPS 140-2/140-3, STIG, CIS Benchmarks, and SOC 2. Proper container security practices, applied consistently, generate the artifact evidence auditors need.
The Cost of Doing Nothing
Every sprint you ship an unhardened LLM inference image is a sprint where a known, exploitable vulnerability rides in production. The argument that “we’ll address CVEs after the model ships” treats security as a backlog item with infinite deferral. It is not. Upstream packages release new CVEs continuously, and GPU base images accumulate them faster than most teams triage.
The operational cost compounds too. A team that normalizes scanner noise loses the ability to respond quickly when a genuinely critical vulnerability surfaces. When Log4Shell-class events happen, teams with disciplined hardening practices patch in hours. Teams carrying 400-finding backlogs measure recovery in weeks.
Regulatory exposure is accelerating for AI specifically. Frameworks like FedRAMP and STIG are being applied to AI infrastructure faster than most platform teams anticipate. Starting with compliant, hardened base images positions you to satisfy audits without emergency remediation sprints.
The longer you wait, the larger the gap between your current image set and a defensible security posture. Each new model version, each new agent runtime, each upstream framework update is another opportunity to close that gap or widen it.